Trainer Extensions¶
In this section, you will learn about the following topics:
How to create your own trainer extension
In the example code of this tutorial, we assume for simplicity that the following symbols are already imported.
import math
import numpy as np
import chainer
from chainer import backend
from chainer import backends
from chainer.backends import cuda
from chainer import Function, FunctionNode, gradient_check, report, training, utils, Variable
from chainer import datasets, initializers, iterators, optimizers, serializers
from chainer import Link, Chain, ChainList
import chainer.functions as F
import chainer.links as L
from chainer.training import extensions
What is trainer Extension?¶
Extension is a callable object that takes a Trainer object as an argument. By adding an Extension to a Trainer using the extend() method, the Extension will be called according to the schedule specified by using a trigger object (See the details in 1. trigger)
The Trainer object contains all information used in a training loop, e.g., models, optimizers, updaters, iterators, and datasets, etc. This makes it possible to change settings such as the learning rate of an optimizer.
Write a simple function¶
You can make a new Extension by writing a simple function which takes a Trainer object as its argument. For example, when you want to reduce the learning rate periodically during training, an lr_drop extension can be written as follows:
def lr_drop(trainer):
trainer.updater.get_optimizer('main').lr *= 0.1
Then you can add this function to a Trainer object via extend() method.
trainer.extend(lr_drop, trigger=(10, 'epoch'))
It lowers the learning rate every 10 epochs by multiplying 0.1 with the current learning rate.
Write a function decorated with @make_extension¶
make_extension() is a decorator that adds some attributes to a given function. For example, the simple extension we created above can be written in this form:
@training.make_extension(trigger=(10, 'epoch'))
def lr_drop(trainer):
trainer.updater.get_optimizer('main').lr *= 0.1
The difference between the above example and this is whether it has a default trigger or not. In the latter case, lr_drop() has its default trigger so that unless another trigger is specified via extend() method, the trigger specified in make_extension() is used by default. The code below acts the same as the former example, i.e., it reduces the learning rate every 10 epochs.
trainer.extend(lr_drop)
There are several attributes you can add using the make_extension() decorator.
1. trigger¶
trigger is an object that takes a Trainer object as an argument and returns a boolean value. If a tuple in the form (period, unit) is given as a trigger, it will be considered as an IntervalTrigger that invokes the extension every period unit. For example, when the given tuple is (10, 'epoch'), the extension will run every 10 epochs.
trigger can also be given to the extend() method that adds an extension to a Trainer object. The priority of triggers is as follows:
When both
extend()and a givenExtensionhavetriggers, thetriggergiven toextend()is used.When
Noneis given toextend()as thetriggerargument and a givenExtensionhastrigger, thetriggergiven to theExtensionis used.When both
triggerattributes inextend()andExtensionareNone, theExtensionwill be fired every iteration.
See the details in the documentation of get_trigger() for more information.
2. default_name¶
An Extension is kept in a dictionary which is a property in a Trainer. This argument gives the name of the Extension. Users will see this name in the keys of the snapshot which is a dictionary generated by serialization.
3. priority¶
As a Trainer object can be assigned multiple Extension objects, the execution order is defined according to the following three values:
PRIORITY_WRITER: The priority for extensions that write some records to the observation dictionary. It includes cases that the extension directly adds values to the observation dictionary, or the extension uses the chainer.report() function to report values to the observation dictionary. Extensions which write something to reporter should go first because other Extensions which read those values may be added.PRIORITY_EDITOR: The priority for extensions that edit the observation dictionary based on already reported values. Extensions which edit some values of reported ones should go after the extensions which write values to reporter but before extensions which read the final values.PRIORITY_READER: The priority for extensions that only read records from the observation dictionary. This is also suitable for extensions that do not use the observation dictionary at all. Extensions which read the reported values should be fired after all the extensions which have other priorities, e.g,PRIORITY_WRITERandPRIORITY_EDITORbecause it should read the final values.
See the details in the documentation of Trainer for more information.
4. finalizer¶
You can specify a function to finalize the extension. It is called once at the end of the training loop, i.e., when run() has finished.
5. initializer¶
You can specify a function which takes a Trainer object as an argument to initialize the extension. It is called once before the training loop begins.
Write a class inherited from the Extension class¶
This is the way to define your own extension with the maximum degree of freedom. You can keep any values inside of the extension and serialize them.
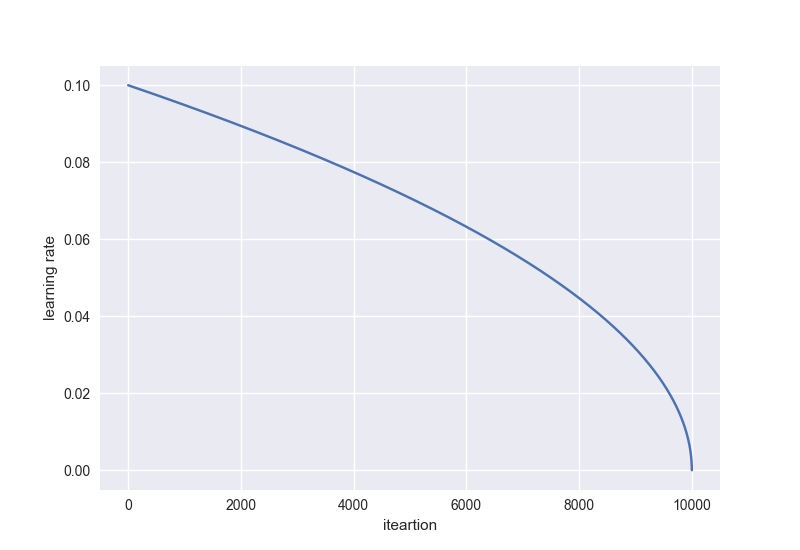
As an example, let’s make an extension that drops the learning rate polynomially. It calculates the learning rate by this equation:
The learning rate will be dropped according to the curve below with \({\rm power} = 0.5\):
class PolynomialShift(training.Extension):
def __init__(self, attr, power, stop_trigger, batchsize=None,
len_dataset=None):
self._attr = attr
self._power = power
self._init = None
self._t = 0
self._last_value = 0
if stop_trigger[1] == 'iteration':
self._maxiter = stop_trigger[0]
elif stop_trigger[1] == 'epoch':
if batchsize is None or len_dataset is None:
raise ValueError(
'When the unit of \'stop_trigger\' is \'epoch\', '
'\'batchsize\' and \'len_dataset\' should be '
'specified to calculate the maximum iteration.')
n_iter_per_epoch = len_dataset / float(batchsize)
self._maxiter = float(stop_trigger[0] * n_iter_per_epoch)
def initialize(self, trainer):
optimizer = trainer.updater.get_optimizer('main')
# ensure that _init is set
if self._init is None:
self._init = getattr(optimizer, self._attr)
def __call__(self, trainer):
self._t += 1
optimizer = trainer.updater.get_optimizer('main')
value = self._init * ((1 - (self._t / self._maxiter)) ** self._power)
setattr(optimizer, self._attr, value)
self._last_value = value
def serialize(self, serializer):
self._t = serializer('_t', self._t)
self._last_value = serializer('_last_value', self._last_value)
if isinstance(self._last_value, np.ndarray):
self._last_value = self._last_value.item()
stop_trigger = (10000, 'iteration')
trainer.extend(PolynomialShift('lr', 0.5, stop_trigger))
This extension PolynomialShift takes five arguments.
attr: The name of the optimizer property you want to update using this extension.power: The power of the above equation to calculate the learning rate.stop_trigger: The trigger given to theTrainerobject to specify when to stop the training loop.batchsize: The training mini-batchsize.len_dataset: The length of the dataset, i.e., the number of data in the training dataset.
This extension calculates the number of iterations which will be performed during training by using stop_trigger, batchsize, and len_dataset, then stores it as a property _maxiter. This property will be used in the __call__() method to update the learning rate. The initialize() method obtains the initial learning rate from the optimizer given to the Trainer object. The serialize() method stores or recovers the properties, _t (number of iterations) and _last_value (the latest learning rate), belonging to this extension.